Troubleshooting Ghost Reset Issues. Need for a device coldStart log entry.
 This thread has been locked for further replies. You can start a new thread to share your ideas or ask questions.
This thread has been locked for further replies. You can start a new thread to share your ideas or ask questions.Clients experiencing loss of connectivity events (buffer circle) randomly. 2 or 3 times per day. Loss of connectivity is the symptom.
Is the Omada device going on-line messages in logs equivalent to an SNMP coldStart (boot) message? Before we can figure out what Omada network is dropping service, seems I'm chasing knowing what is going on.
I'm having no direct cause insight from Omada Log which device went off-line and the order in which they restored. The clue starts in the Networking or Statistics screen by seeing gaps in traffic graph. Digging into logs, we simply see clients being declared off-line at a particular AP, and then about 33 seconds later they start being associated again. The AP devices never signs off or shows coming back on-line. Say a dozen clients all get declared off-line at an AP, and then a minute later these same clients get declared on-line again at that AP. If this is the GW that seems to ghost, all clients will go through this process.
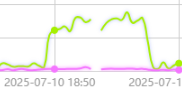
There are clues available if the problem is limited to a particular switch, it's devices and clients, or a wider disruption.... Was it just an AP resetting? If ALL AP's are associating devices, then the GW/Router reset. I have messaging that also shows the OC200 going off and on line OC200_D9F759 went offline from network "Default" on Gateway(connected time:193h50m connected, traffic: 9.17MB).... OC200_D9F759 went online on Gateway on Default network.
Suspect that devices or GW rebooting is not absolutely displayed. To help localize issues, knowing that the absolute first message sent and logged by any Omada device upon power up or reboot will be coldStart. Of course, communication and a log server to capture must be functioning for this to be successful. For example, A coldStart message in SNMP. Is something similar possible in the Omada log?
System consists of 10 AP's in 3 buildings with 3 Omada PoE switches, 1 per building, one central GW and OC200 Controller. of 2 SL terminals, 1 SL + GW + OC200 and half of the AP's are on UPS, so should be sane to record unprotected devices being rebooting. Default VLAN 1, VLAN for 2nd SSID, and a 3rd point to point VLAN for transport purposes.
Insight appreciated... or if I can did deeper into a device to determine if and when it rebooted.
- Copy Link
- Subscribe
- Bookmark
- Report Inappropriate Content
@RF_Dude the host Omada system where I replaced suspected EAP225 creating network issues with a new EAP610 is now working well. No more traffic graph gaps (suggesting OC200 reboot). No more people complaining about buffering issues (things worked most of the time, but connectivity would not remain stable through a movie), and unexplained log entries showing clients all going off-line from a device (EAP) then reappearing a minute later. The replacement EAP610 is working perfectly on the same Ethernet cable.
The erant EAP225 was installed on a residental test system with very few users and a short cable to the GW/Controller. Seems to work fine most of the time, but I've experienced WiFi call drops and buffering issues where there previously were none. Poltergeist symptoms as what was happening in the other system. Wishy-washy way to troubleshoot. Due to lack of details and cause-effect, resulting in months tolerating this problem!
Disconnected EAP's show under ALERT. Controller remains sane and available to log missed heartbeat. Reconnecting devices are listed under EVENTS.
I've opened a Feature Request for a coldStart / boot / reset log entry that would help these matters and any where infrastructure devices (EAP, Switches, GW, Controller) do a restart or reboot. If a heartbeat exists to Omada cloud servers, loss of this can and should also be logged. Kinda basic stuff that most equipment logs provide. If a watchdog resets an EAP / SW / GW / OC or reboots for whatever reason, it is a catch-all indicator of issues and should be in the event log! Thank you!
- Copy Link
- Report Inappropriate Content

RF_Dude wrote
Clients experiencing loss of connectivity events (buffer circle) randomly. 2 or 3 times per day. Loss of connectivity is the symptom.
Is the Omada device going on-line messages in logs equivalent to an SNMP coldStart (boot) message? Before we can figure out what Omada network is dropping service, seems I'm chasing knowing what is going on.
I'm having no direct cause insight from Omada Log which device went off-line and the order in which they restored. The clue starts in the Networking or Statistics screen by seeing gaps in traffic graph. Digging into logs, we simply see clients being declared off-line at a particular AP, and then about 33 seconds later they start being associated again. The AP devices never signs off or shows coming back on-line. Say a dozen clients all get declared off-line at an AP, and then a minute later these same clients get declared on-line again at that AP. If this is the GW that seems to ghost, all clients will go through this process.
There are clues available if the problem is limited to a particular switch, it's devices and clients, or a wider disruption.... Was it just an AP resetting? If ALL AP's are associating devices, then the GW/Router reset. I have messaging that also shows the OC200 going off and on line OC200_D9F759 went offline from network "Default" on Gateway(connected time:193h50m connected, traffic: 9.17MB).... OC200_D9F759 went online on Gateway on Default network.
Suspect that devices or GW rebooting is not absolutely displayed. To help localize issues, knowing that the absolute first message sent and logged by any Omada device upon power up or reboot will be coldStart. Of course, communication and a log server to capture must be functioning for this to be successful. For example, A coldStart message in SNMP. Is something similar possible in the Omada log?
System consists of 10 AP's in 3 buildings with 3 Omada PoE switches, 1 per building, one central GW and OC200 Controller. of 2 SL terminals, 1 SL + GW + OC200 and half of the AP's are on UPS, so should be sane to record unprotected devices being rebooting. Default VLAN 1, VLAN for 2nd SSID, and a 3rd point to point VLAN for transport purposes.
Insight appreciated... or if I can did deeper into a device to determine if and when it rebooted.
Questions:
Does this happen to wired devices?
I am not sure, but from the description, it appears to be a wireless issue. Not for the wired one.
Offline does not mean the Internet is cut off. That log is about the LAN connection.
If this issue does not happen to the wired devices, then I assume that could be the wireless clients drops from the AP.
- Copy Link
- Report Inappropriate Content
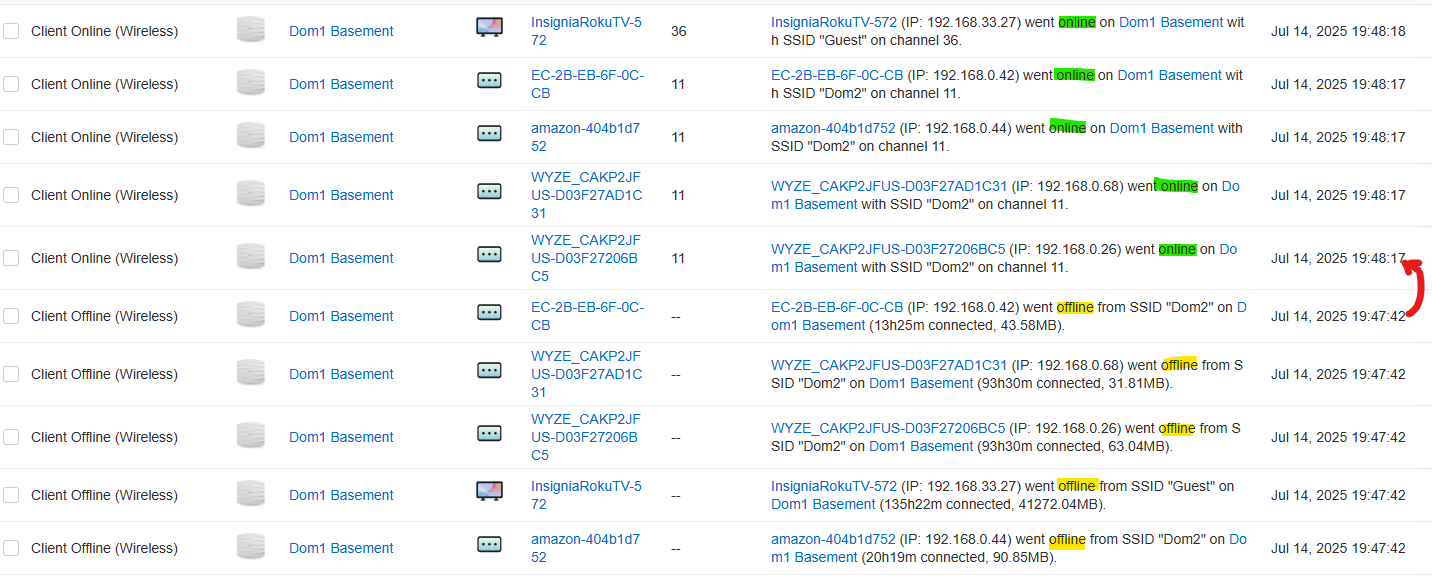
@RF_Dude I'm having a really difficult time. Various EAP's... 245 (5.0.3 and 5.05 firmware), EAP650, EAP683, all exhibiting the following what looks very similar. All are operating on the latest stable firmware. The system is unstable. These are "assumed" resets... None create a coldBoot message to confirm that they rebooted (imagine your own swear word here), so we are guessing or you know for sure they didn't reboot, just "paused" operation? Today the OMADA system had 5 10m gaps showing in the dashboard or traffic statistics. That might be where the GW OC200 goes reboots. The AP's are doing it much more often.
I've found one client that is an Espressif Inc Mac ID that seem to connect and disconnect in unknown (to me) patterns with no data transferred. Shows up as wired even though it is an ESP32 device according to ChatGPT Spoofs about 6 Mac ID's ... I've blocked all that I've seen that "could" be creating traffic that "may" be negatively affecting the Omada system. This is pretty much grasping at straws and hoping for stability.
People are streaming... reality is this is how people use Starlink, WiFi, Internet... so will observe every burp or upset the TP-LINK system creates. Their TV's or devices show the spinning buffer... the community is not happy with this... Thanks for useful vectors where to look next.
- Copy Link
- Report Inappropriate Content
RF_Dude wrote
@RF_Dude I'm having a really difficult time. Various EAP's... 245 (5.0.3 and 5.05 firmware), EAP650, EAP683, all exhibiting the following what looks very similar. All are operating on the latest stable firmware. The system is unstable. These are "assumed" resets... None create a coldBoot message to confirm that they rebooted (imagine your own swear word here), so we are guessing or you know for sure they didn't reboot, just "paused" operation? Today the OMADA system had 5 10m gaps showing in the dashboard or traffic statistics. That might be where the GW OC200 goes reboots. The AP's are doing it much more often.
I've found one client that is an Espressif Inc Mac ID that seem to connect and disconnect in unknown (to me) patterns with no data transferred. Shows up as wired even though it is an ESP32 device according to ChatGPT Spoofs about 6 Mac ID's ... I've blocked all that I've seen that "could" be creating traffic that "may" be negatively affecting the Omada system. This is pretty much grasping at straws and hoping for stability.
People are streaming... reality is this is how people use Starlink, WiFi, Internet... so will observe every burp or upset the TP-LINK system creates. Their TV's or devices show the spinning buffer... the community is not happy with this... Thanks for useful vectors where to look next.
If this is a wireless issue, I recommend you submit a new post on the AP page.
Everything so far based on what I saw is about the controller and wireless. If there is a problem that specifically relates to the router, I can work with you yet this wireless issue is not my realm.
- Copy Link
- Report Inappropriate Content
@Clive_A Over the last 6 months (or more) one EAP225 Outdoor was failed softly. Needing reboots as it seemed unstable. Things like connected at 100 Mbps instead of 1000Mbps. Rebooting or random loop shutdowns that would occur. It exists in a site with 10 AP's 9 of which are wired and 1 that is Mesh connected. I suspected, but could not prove that occassionally this EAP225 would cause the LOOP issue resulting in a spanning tree loop switch shut down. Other performance issues were manifesting themselves, including occassional buffering that clients experienced, and gaps in traffic graphs.
As noted in the original post, the granularity of the logs for equipment error made direct cause-effect difficult. Some spanning tree loops were captured in the logs. Many others were not, but manifested as a lot of clients going off-line then coming back a minute later... no equipment errors logged.
FINALLY, this problem EAP225 went down hard, meaning 100 Mbps Ethernet connection, attempting mesh connections and would not stay operating for longer than a few minutes despite remotely forced reboots. Device status disconnected, or adopting. I replaced it with an EAP610.
Network has been stable since. Clients have observed this and commented postively. Seems during the EAP225 reboot process, it would reject the wired Ethernet connection, and attempt a MESH connection. During this process it occassionally allowed a loop to occur. Even when nothing was captured in the log, a loss of traffic graph continuity showed something was up. Perhaps a management messaging storm caused the OC200 to reboot which showed in the traffic graph? That is my interpretation.
I'm able to watch this SL connected system closely. And with only 10 AP's, not overly complex. A slow or soft failure is the worst. If this was a larger network... how to quickly identify thise sort of failures without subjecting clients to lengthy performance issues while the operator is pulling out their hair? I've identified logging reboots (coldboot... warmboot) as one helpful feature to indicate problems. More equipment (device) fault logs are required please!
If you like I can repost this into the AP forum. Or new features? While in this case an AP was at fault, $%# happens... having better equipment logs across the board (GW, Switch, AP, Controller) is the ask.
- Copy Link
- Report Inappropriate Content
RF_Dude wrote
@Clive_A Over the last 6 months (or more) one EAP225 Outdoor was failed softly. Needing reboots as it seemed unstable. Things like connected at 100 Mbps instead of 1000Mbps. Rebooting or random loop shutdowns that would occur. It exists in a site with 10 AP's 9 of which are wired and 1 that is Mesh connected. I suspected, but could not prove that occassionally this EAP225 would cause the LOOP issue resulting in a spanning tree loop switch shut down. Other performance issues were manifesting themselves, including occassional buffering that clients experienced, and gaps in traffic graphs.
As noted in the original post, the granularity of the logs for equipment error made direct cause-effect difficult. Some spanning tree loops were captured in the logs. Many others were not, but manifested as a lot of clients going off-line then coming back a minute later... no equipment errors logged.
FINALLY, this problem EAP225 went down hard, meaning 100 Mbps Ethernet connection, attempting mesh connections and would not stay operating for longer than a few minutes despite remotely forced reboots. Device status disconnected, or adopting. I replaced it with an EAP610.
Network has been stable since. Clients have observed this and commented postively. Seems during the EAP225 reboot process, it would reject the wired Ethernet connection, and attempt a MESH connection. During this process it occassionally allowed a loop to occur. Even when nothing was captured in the log, a loss of traffic graph continuity showed something was up. Perhaps a management messaging storm caused the OC200 to reboot which showed in the traffic graph? That is my interpretation.
I'm able to watch this SL connected system closely. And with only 10 AP's, not overly complex. A slow or soft failure is the worst. If this was a larger network... how to quickly identify thise sort of failures without subjecting clients to lengthy performance issues while the operator is pulling out their hair? I've identified logging reboots (coldboot... warmboot) as one helpful feature to indicate problems. More equipment (device) fault logs are required please!
If you like I can repost this into the AP forum. Or new features? While in this case an AP was at fault, $%# happens... having better equipment logs across the board (GW, Switch, AP, Controller) is the ask.
If you say the EAP fall back to 100Mbps if you are using a gigabit connection for PoE and data, I'd say that is a problem with the Ethernet cable.
I am not sure if there's a problem with the mesh, but if you have EAP WIFI5 series, this should not be a problem with the mesh loop.
If all firmware are up-to-date, mesh should not cause a loop.
- Copy Link
- Report Inappropriate Content
@Clive_A Observations....
- Some previous GEN devices like EAP225 and EAP245 have been intermittent for me... or picky about Ethernet cables. Not the first time I've either replaced cable, or EAP due to this 100 Mbps speed indicating some sort of trouble. Cables ring fine using continuity.
- EAP610 is operating just fine for 2 weeks on the same cable that the failed EAP225 Outdoor used.
- New Omada cable diagnostic feature reports this cable is Normal and 28m in length.
- I've put the failed EAP225 into another site used for testing. Different GW, cable, environment. Lets see.
- Copy Link
- Report Inappropriate Content
@RF_Dude the host Omada system where I replaced suspected EAP225 creating network issues with a new EAP610 is now working well. No more traffic graph gaps (suggesting OC200 reboot). No more people complaining about buffering issues (things worked most of the time, but connectivity would not remain stable through a movie), and unexplained log entries showing clients all going off-line from a device (EAP) then reappearing a minute later. The replacement EAP610 is working perfectly on the same Ethernet cable.
The erant EAP225 was installed on a residental test system with very few users and a short cable to the GW/Controller. Seems to work fine most of the time, but I've experienced WiFi call drops and buffering issues where there previously were none. Poltergeist symptoms as what was happening in the other system. Wishy-washy way to troubleshoot. Due to lack of details and cause-effect, resulting in months tolerating this problem!
Disconnected EAP's show under ALERT. Controller remains sane and available to log missed heartbeat. Reconnecting devices are listed under EVENTS.
I've opened a Feature Request for a coldStart / boot / reset log entry that would help these matters and any where infrastructure devices (EAP, Switches, GW, Controller) do a restart or reboot. If a heartbeat exists to Omada cloud servers, loss of this can and should also be logged. Kinda basic stuff that most equipment logs provide. If a watchdog resets an EAP / SW / GW / OC or reboots for whatever reason, it is a catch-all indicator of issues and should be in the event log! Thank you!
- Copy Link
- Report Inappropriate Content
Information
Helpful: 0
Views: 842
Replies: 7
Voters 0
No one has voted for it yet.