6.2.10.17 - Controller Unresponsive After Auto-Backup Due to OOM
What seems to be somewhat randomly, my controller which I upgraded to 6.2.10.17 recently will go into a state of being unresponsive. I notice this because I have a https site monitor that verifies if some apps are up and this triggers the alerts.
4/30 - 1:20 AM Eastern - controller was not responsive over https; CPU spike to 100% usage on the two cores it's allocated
5/1 - unknown - controller was responsive but all devices were cycling through provisioning and failing (I do not have logs from this time period)
5/2 - 1:20 AM Eastern - controller was not responsive over https
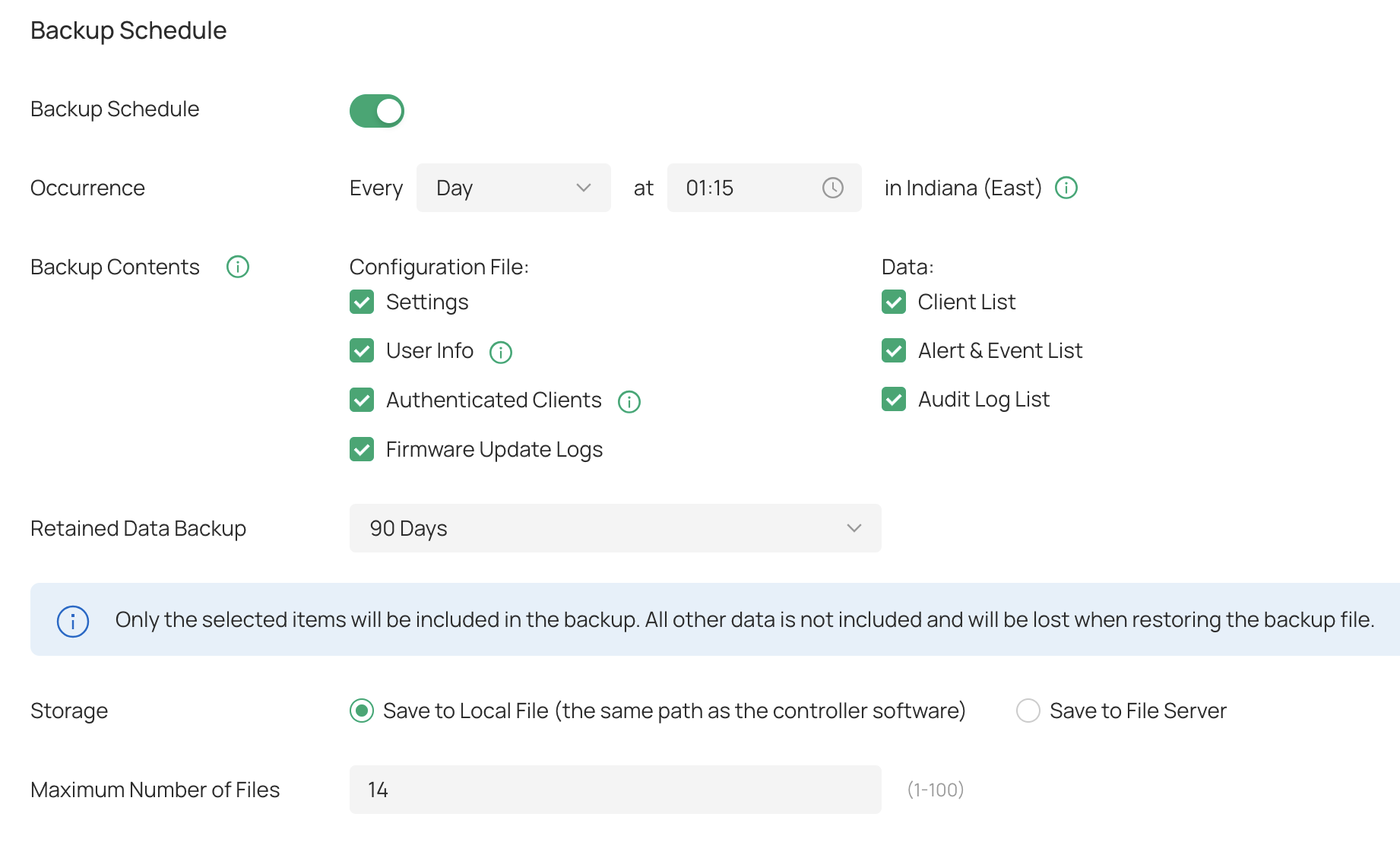
All three times a controller restart was needed to bring the app back up. Unfortunately I currently do not have the logs from around 1:20 AM so I can't see what might be occurring at that time but it seems to be some scheduled task based on how regularly it seems to be happening at this time. The one thing I can think of right around this time is that I do have automatic backups enabled and they happen to run at 1:15 AM every day. My site monitor checks every 5 minutes so it seems logical that it's related to backups because the first check after kicking off the backups would be at 1:20 AM.
Here's what it generally shows in the logs without the multi-line details (those can be found in the link to the gist):
05-02-2026 02:15:41.770 INFO [tcp-message-executor-21-3] [] c.t.s.e.s.c.n(): disconnect clear spake2 info
05-02-2026 02:15:41.770 INFO [tcp-message-executor-21-3] [] c.t.s.e.s.c.n(): [STAT] {"device":"f2dbvEpxkxpkOgnK3WwlkejApUo7v1v1SzsXTSdmezA=","operation":"Offline","connection-times":69 }
05-02-2026 02:15:41.770 INFO [tcp-message-executor-21-3] [] c.t.s.e.s.c.c(): connection disconnected by device, mac:f2dbvEpxkxpkOgnK3WwlkejApUo7v1v1SzsXTSdmezA=
05-02-2026 02:15:41.773 INFO [manage-work-group-5] [] c.t.s.o.m.d.p.t.c(): [stat] {"device":"f2dbvEpxkxpkOgnK3WwlkejApUo7v1v1SzsXTSdmezA=","omadacId":"OmadacId(1884487c406a9ac81b80b4f25313c67a)","status":"CONNECTED_ERROR"}
05-02-2026 02:15:41.773 INFO [manage-work-group-5] [] c.t.s.o.m.d.p.t.c(): Device f2dbvEpxkxpkOgnK3WwlkejApUo7v1v1SzsXTSdmezA= OmadacId(1884487c406a9ac81b80b4f25313c67a) changed to status CONNECTED_ERROR, which don't need to handle.
05-02-2026 02:15:41.785 INFO [server-comm-pool-1] [] c.t.s.e.s.c.n(): [STAT] {"device":"f2dbvEpxkxpkOgnK3WwlkejApUo7v1v1SzsXTSdmezA=","operation":"Online","connection-times":70}
05-02-2026 02:15:41.988 INFO [server-comm-pool-4] [] c.t.s.e.s.c.h.EcspV2DeviceContextHelper(): close old channel mac A8-29-48-93-7A-C4
05-02-2026 02:15:41.994 INFO [manage-work-group-11] [] c.t.s.o.m.d.p.t.c(): [stat] {"device":"f2dbvEpxkxpkOgnK3WwlkejApUo7v1v1SzsXTSdmezA=","omadacId":"OmadacId(1884487c406a9ac81b80b4f25313c67a)","status":"CONNECTED"}
05-02-2026 02:15:41.994 INFO [manage-work-group-11] [] c.t.s.o.m.d.p.t.c(): Device f2dbvEpxkxpkOgnK3WwlkejApUo7v1v1SzsXTSdmezA= OmadacId(1884487c406a9ac81b80b4f25313c67a) changed to status CONNECTED, which don't need to handle.
05-02-2026 02:15:41.998 INFO [manage-work-group-8] [] c.t.s.o.m.d.d.m.r.c(): Success get adopt limiter device DeviceMac(f2dbvEpxkxpkOgnK3WwlkejApUo7v1v1SzsXTSdmezA=) with count 0.
05-02-2026 02:15:42.002 INFO [manage-work-group-8] [] c.t.s.o.m.d.d.m.r.c(): send v2 rebuild reply[reset=false] to omadacId OmadacId(1884487c406a9ac81b80b4f25313c67a) & mac DeviceMac(f2dbvEpxkxpkOgnK3WwlkejApUo7v1v1SzsXTSdmezA=)
05-02-2026 02:15:42.813 INFO [server-comm-pool-1] [] c.t.s.e.s.c.n(): [STAT] {"device":"2AKZ3ZZCbRwObLMmiKn/cjtbP0QmBywQ50ZyKshAyqQ=","operation":"Online","connection-times":70}
05-02-2026 02:15:43.020 INFO [server-comm-pool-3] [] c.t.s.e.s.c.h.EcspV2DeviceContextHelper(): close old channel mac 98-BA-5F-62-CF-D8
05-02-2026 02:15:43.046 INFO [manage-work-group-13] [] c.t.s.o.m.d.p.t.c(): [stat] {"device":"2AKZ3ZZCbRwObLMmiKn/cjtbP0QmBywQ50ZyKshAyqQ=","omadacId":"OmadacId(1884487c406a9ac81b80b4f25313c67a)","status":"CONNECTED"}
05-02-2026 02:15:43.046 INFO [manage-work-group-13] [] c.t.s.o.m.d.p.t.c(): Device 2AKZ3ZZCbRwObLMmiKn/cjtbP0QmBywQ50ZyKshAyqQ= OmadacId(1884487c406a9ac81b80b4f25313c67a) changed to status CONNECTED, which don't need to handle.
05-02-2026 02:15:43.047 INFO [manage-work-group-15] [] c.t.s.o.m.d.d.m.r.c(): Success get adopt limiter device DeviceMac(2AKZ3ZZCbRwObLMmiKn/cjtbP0QmBywQ50ZyKshAyqQ=) with count 0.
05-02-2026 02:15:43.057 INFO [manage-work-group-15] [] c.t.s.o.m.d.d.m.r.c(): send v2 rebuild reply[reset=false] to omadacId OmadacId(1884487c406a9ac81b80b4f25313c67a) & mac DeviceMac(2AKZ3ZZCbRwObLMmiKn/cjtbP0QmBywQ50ZyKshAyqQ=)
05-02-2026 02:15:45.999 INFO [tcp-message-executor-21-2] [] c.t.s.e.s.c.n(): disconnect clear spake2 info
05-02-2026 02:15:45.999 INFO [tcp-message-executor-21-2] [] c.t.s.e.s.c.n(): [STAT] {"device":"u8x5o69fmxZwbY+dfn3ieRDlCZ+jQhuKoqe41lGn1tA=","operation":"Offline","connection-times":69 }
05-02-2026 02:15:45.999 INFO [tcp-message-executor-21-2] [] c.t.s.e.s.c.c(): connection disconnected by device, mac:u8x5o69fmxZwbY+dfn3ieRDlCZ+jQhuKoqe41lGn1tA=
05-02-2026 02:15:46.000 WARN [netty-tcp-server-worker-20-1] [] i.n.c.ChannelInitializer(): Failed to initialize a channel. Closing: [id: 0xbaeac279, L:/192.168.2.160:29814 - R:/192.168.0.3:33665]
05-02-2026 02:15:46.001 WARN [netty-tcp-server-worker-20-1] [] i.n.c.AbstractChannelHandlerContext(): Failed to submit an exceptionCaught() event.
05-02-2026 02:15:46.001 WARN [netty-tcp-server-worker-20-1] [] i.n.c.AbstractChannelHandlerContext(): The exceptionCaught() event that was failed to submit was:
05-02-2026 02:15:46.001 WARN [netty-tcp-server-worker-20-1] [] i.n.c.AbstractChannelHandlerContext(): Failed to submit an exceptionCaught() event.
05-02-2026 02:15:46.002 INFO [manage-work-group-10] [] c.t.s.o.m.d.p.t.c(): [stat] {"device":"u8x5o69fmxZwbY+dfn3ieRDlCZ+jQhuKoqe41lGn1tA=","omadacId":"OmadacId(1884487c406a9ac81b80b4f25313c67a)","status":"CONNECTED_ERROR"}
05-02-2026 02:15:46.001 WARN [netty-tcp-server-worker-20-1] [] i.n.c.AbstractChannelHandlerContext(): The exceptionCaught() event that was failed to submit was:
05-02-2026 02:15:46.002 INFO [manage-work-group-10] [] c.t.s.o.m.d.p.t.c(): Device u8x5o69fmxZwbY+dfn3ieRDlCZ+jQhuKoqe41lGn1tA= OmadacId(1884487c406a9ac81b80b4f25313c67a) changed to status CONNECTED_ERROR, which don't need to handle.
05-02-2026 02:15:46.001 WARN [netty-tcp-server-worker-20-1] [] i.n.c.AbstractChannelHandlerContext(): Failed to submit an exceptionCaught() event.
05-02-2026 02:15:46.001 WARN [netty-tcp-server-worker-20-1] [] i.n.c.AbstractChannelHandlerContext(): The exceptionCaught() event that was failed to submit was:
05-02-2026 02:15:46.001 WARN [netty-tcp-server-worker-20-1] [] i.n.c.AbstractChannelHandlerContext(): Failed to submit an exceptionCaught() event.
05-02-2026 02:15:46.001 WARN [netty-tcp-server-worker-20-1] [] i.n.c.AbstractChannelHandlerContext(): The exceptionCaught() event that was failed to submit was:
05-02-2026 02:15:46.001 WARN [netty-tcp-server-worker-20-1] [] i.n.c.AbstractChannelHandlerContext(): Failed to submit an exceptionCaught() event.
05-02-2026 02:15:46.001 WARN [netty-tcp-server-worker-20-1] [] i.n.c.AbstractChannelHandlerContext(): The exceptionCaught() event that was failed to submit was:
05-02-2026 02:15:47.991 WARN [RxComputationThreadPool-4] [] c.t.s.o.m.d.p.t.f.a(): send rebuild response to omadacId OmadacId(1884487c406a9ac81b80b4f25313c67a) & mac DeviceMac(f2dbvEpxkxpkOgnK3WwlkejApUo7v1v1SzsXTSdmezA=) error, <removed due to filter>[addressDTO=<null>,errCode=2600,msg=ERR_DEVICE_SEND_TCP_TIMEOUT,result=<null>]
05-02-2026 02:15:49.605 INFO [tcp-message-executor-21-3] [] c.t.s.e.s.c.n(): disconnect clear spake2 info
05-02-2026 02:15:49.605 INFO [tcp-message-executor-21-3] [] c.t.s.e.s.c.n(): [STAT] {"device":"SzA2plzJtKjnG2roVl5v+pFd69z8QCP1QG5Qzjv79+M=","operation":"Offline","connection-times":70 }
05-02-2026 02:15:49.605 INFO [tcp-message-executor-21-3] [] c.t.s.e.s.c.c(): connection disconnected by device, mac:SzA2plzJtKjnG2roVl5v+pFd69z8QCP1QG5Qzjv79+M=
05-02-2026 02:15:49.607 INFO [manage-work-group-2] [] c.t.s.o.m.d.p.t.c(): [stat] {"device":"SzA2plzJtKjnG2roVl5v+pFd69z8QCP1QG5Qzjv79+M=","omadacId":"OmadacId(1884487c406a9ac81b80b4f25313c67a)","status":"CONNECTED_ERROR"}
05-02-2026 02:15:49.607 INFO [manage-work-group-2] [] c.t.s.o.m.d.p.t.c(): Device SzA2plzJtKjnG2roVl5v+pFd69z8QCP1QG5Qzjv79+M= OmadacId(1884487c406a9ac81b80b4f25313c67a) changed to status CONNECTED_ERROR, which don't need to handle.
05-02-2026 02:15:49.637 INFO [server-comm-pool-1] [] c.t.s.e.s.c.n(): [STAT] {"device":"SzA2plzJtKjnG2roVl5v+pFd69z8QCP1QG5Qzjv79+M=","operation":"Online","connection-times":71}
05-02-2026 02:15:49.845 INFO [server-comm-pool-0] [] c.t.s.e.s.c.h.EcspV2DeviceContextHelper(): close old channel mac 60-A4-B7-F3-5A-A8
05-02-2026 02:15:49.860 INFO [manage-work-group-14] [] c.t.s.o.m.d.p.t.c(): [stat] {"device":"SzA2plzJtKjnG2roVl5v+pFd69z8QCP1QG5Qzjv79+M=","omadacId":"OmadacId(1884487c406a9ac81b80b4f25313c67a)","status":"CONNECTED"}
05-02-2026 02:15:49.860 INFO [manage-work-group-14] [] c.t.s.o.m.d.p.t.c(): Device SzA2plzJtKjnG2roVl5v+pFd69z8QCP1QG5Qzjv79+M= OmadacId(1884487c406a9ac81b80b4f25313c67a) changed to status CONNECTED, which don't need to handle.
05-02-2026 02:15:49.864 INFO [manage-work-group-4] [] c.t.s.o.m.d.d.m.r.c(): Success get adopt limiter device DeviceMac(SzA2plzJtKjnG2roVl5v+pFd69z8QCP1QG5Qzjv79+M=) with count 0.
05-02-2026 02:15:49.867 INFO [manage-work-group-4] [] c.t.s.o.m.d.d.m.r.c(): send v2 rebuild reply[reset=false] to omadacId OmadacId(1884487c406a9ac81b80b4f25313c67a) & mac DeviceMac(SzA2plzJtKjnG2roVl5v+pFd69z8QCP1QG5Qzjv79+M=)
05-02-2026 02:15:50.021 INFO [server-comm-pool-1] [] c.t.s.e.s.c.n(): [STAT] {"device":"u8x5o69fmxZwbY+dfn3ieRDlCZ+jQhuKoqe41lGn1tA=","operation":"Online","connection-times":70}
05-02-2026 02:15:50.226 INFO [server-comm-pool-4] [] c.t.s.e.s.c.h.EcspV2DeviceContextHelper(): close old channel mac A8-29-48-93-7D-85
05-02-2026 02:15:50.233 INFO [manage-work-group-1] [] c.t.s.o.m.d.p.t.c(): [stat] {"device":"u8x5o69fmxZwbY+dfn3ieRDlCZ+jQhuKoqe41lGn1tA=","omadacId":"OmadacId(1884487c406a9ac81b80b4f25313c67a)","status":"CONNECTED"}
05-02-2026 02:15:50.233 INFO [manage-work-group-1] [] c.t.s.o.m.d.p.t.c(): Device u8x5o69fmxZwbY+dfn3ieRDlCZ+jQhuKoqe41lGn1tA= OmadacId(1884487c406a9ac81b80b4f25313c67a) changed to status CONNECTED, which don't need to handle.
05-02-2026 02:15:50.235 INFO [manage-work-group-0] [] c.t.s.o.m.d.d.m.r.c(): Success get adopt limiter device DeviceMac(u8x5o69fmxZwbY+dfn3ieRDlCZ+jQhuKoqe41lGn1tA=) with count 0.
05-02-2026 02:15:50.239 INFO [manage-work-group-0] [] c.t.s.o.m.d.d.m.r.c(): send v2 rebuild reply[reset=false] to omadacId OmadacId(1884487c406a9ac81b80b4f25313c67a) & mac DeviceMac(u8x5o69fmxZwbY+dfn3ieRDlCZ+jQhuKoqe41lGn1tA=)
05-02-2026 02:15:52.221 WARN [RxComputationThreadPool-3] [] c.t.s.o.m.d.p.t.f.a(): send rebuild response to omadacId OmadacId(1884487c406a9ac81b80b4f25313c67a) & mac DeviceMac(u8x5o69fmxZwbY+dfn3ieRDlCZ+jQhuKoqe41lGn1tA=) error, <removed due to filter>[addressDTO=<null>,errCode=2600,msg=ERR_DEVICE_SEND_TCP_TIMEOUT,result=<null>]
05-02-2026 02:15:54.742 INFO [log-dst-info-event-pool-40] [] c.t.s.o.l.p.c.f.e(): Failed to replace device name in log content,log omadaLogEnum:L_C_CONN, log key: null
05-02-2026 02:15:54.742 INFO [log-dst-info-event-pool-40] [] c.t.s.o.l.p.c.f.e(): Failed to replace device name in log content,log omadaLogEnum:L_C_CONN, log key: null
Here is what I've captured on what seems to be the end to end logs in what appears to be a repeating pattern:
https://gist.github.com/mbentley/93f71b349e4df214d48e389c9790c0e2
I have a longer log capture from 05-02-2026 02:15:20.641 to 05-02-2026 03:18:25.069 if it is helpful - it's 16 MB uncompressed though