OC300 failes to massivly upgrade devices Firmware
I've been writing this post while figuring this out, so please bear with me.
This past year has been a headache to upgrade devices firmware.
Every time I log in there are a large amount of devices with outdated Firmware.
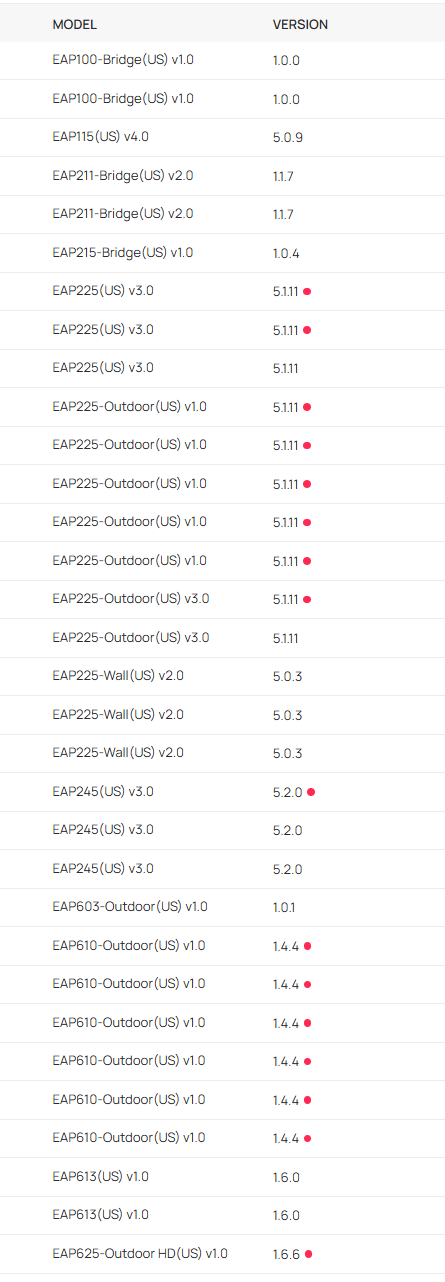
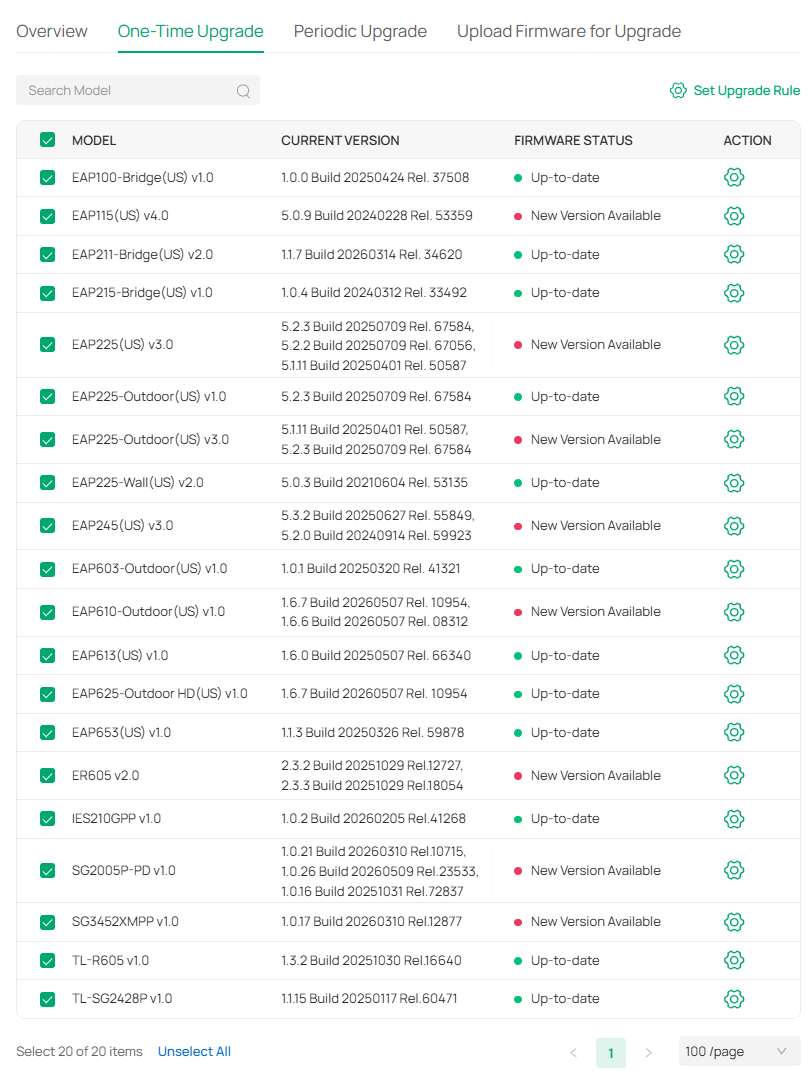
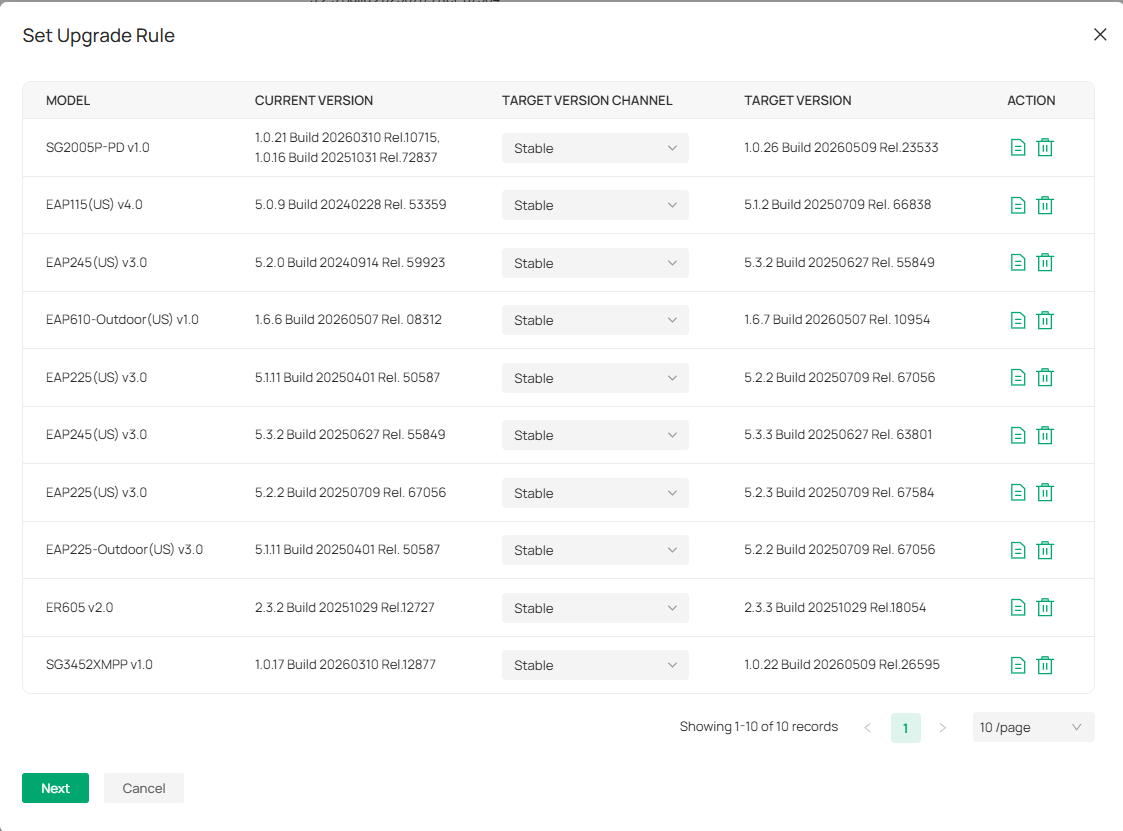
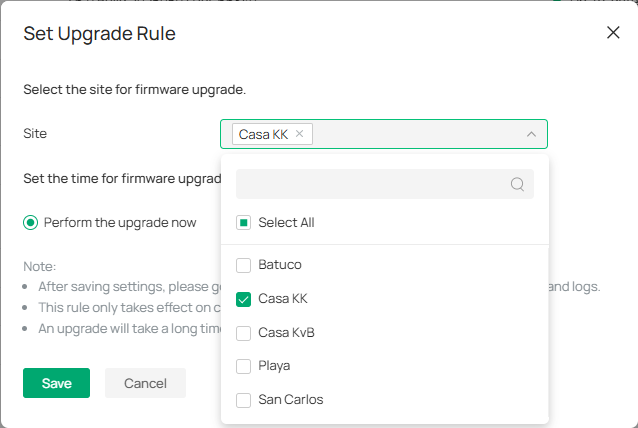
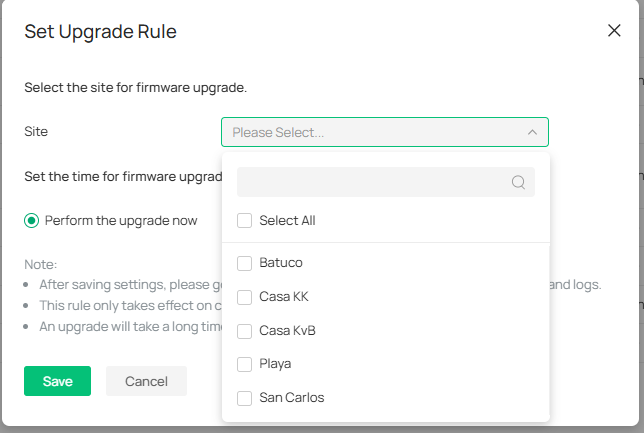
I've tried several ways to update the devices, which used to be easy untill they moved it to the global view with a complicated select model/ select version/ select site scheme. They had eliminated every way to simply select a device and upgrade its firmware.
More and more devices are lagging as FW versions are piling up.
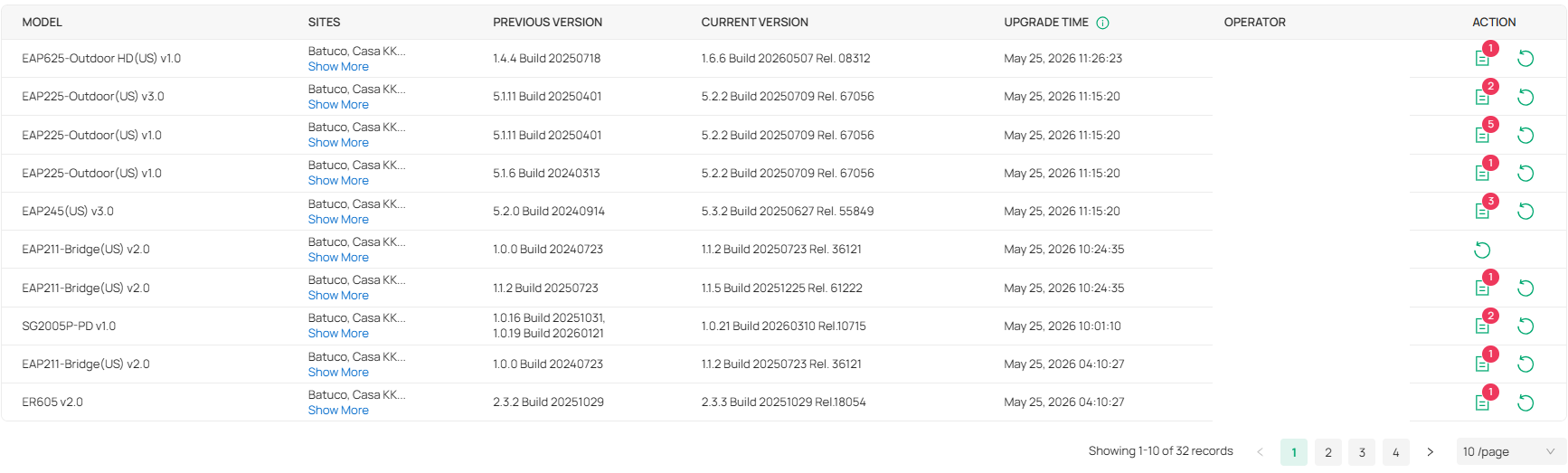
This scheduling of a one-time upgrade has been horrible. I thought it never worked as I'm not getting any feedback of the upgrading process beyond the "Failed device list" in the action column.
Note: I can't capture the whole liste because due to a bug in many views the next section covers the xx/page button, even preventing to select the last visible option. In this case I can only select 5/ and 10/. 20/ is unselectable.
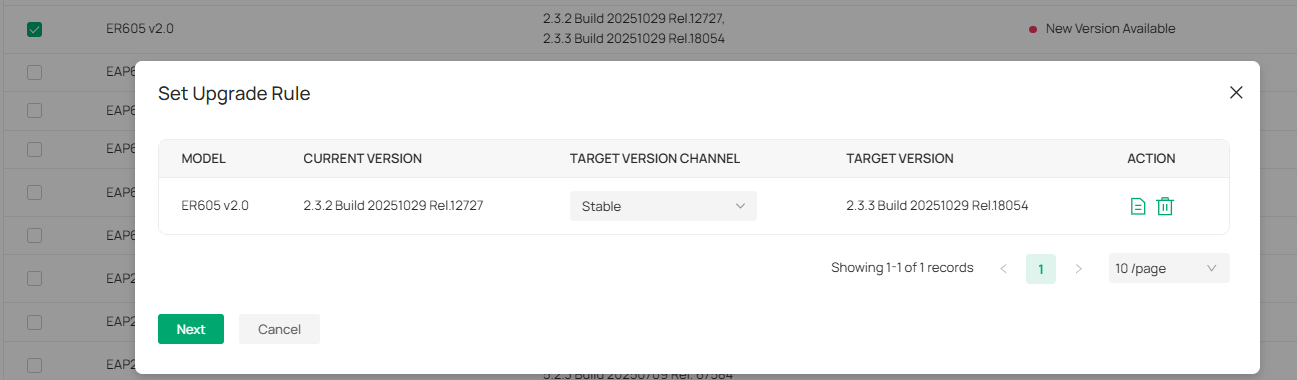
Now I'm noticing there seems to be one, and only one, device that upgrades every time I try upgrading. No matter if I only try it with one site, one device model, or whatever low number of devices combination I try. I only figured this out because there is only one device with a recent UPTIME after I try the upgrading process.
So now that the single device upgrade is back, (don't know since which omada version) I've started to upgrade device by device trying to make manually sure I'm not upgrading a device that is behind another upgrading device, which is very time consuming and difficult, given I'm on a farm with multi hop wired, bridged and mesh devices, not counting I'm managing several sites with the same OC300.
What used to be the "batch upgrade" option that inteligently started with the righ-most topoloy devices untill reaching the router seems to be missing and broken ever since omada v6.
The new (back again) single device upgrade option is hindered by the fact that the FW upgrade queue is very limited to only 4 devices at a time.
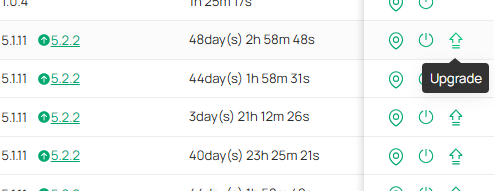
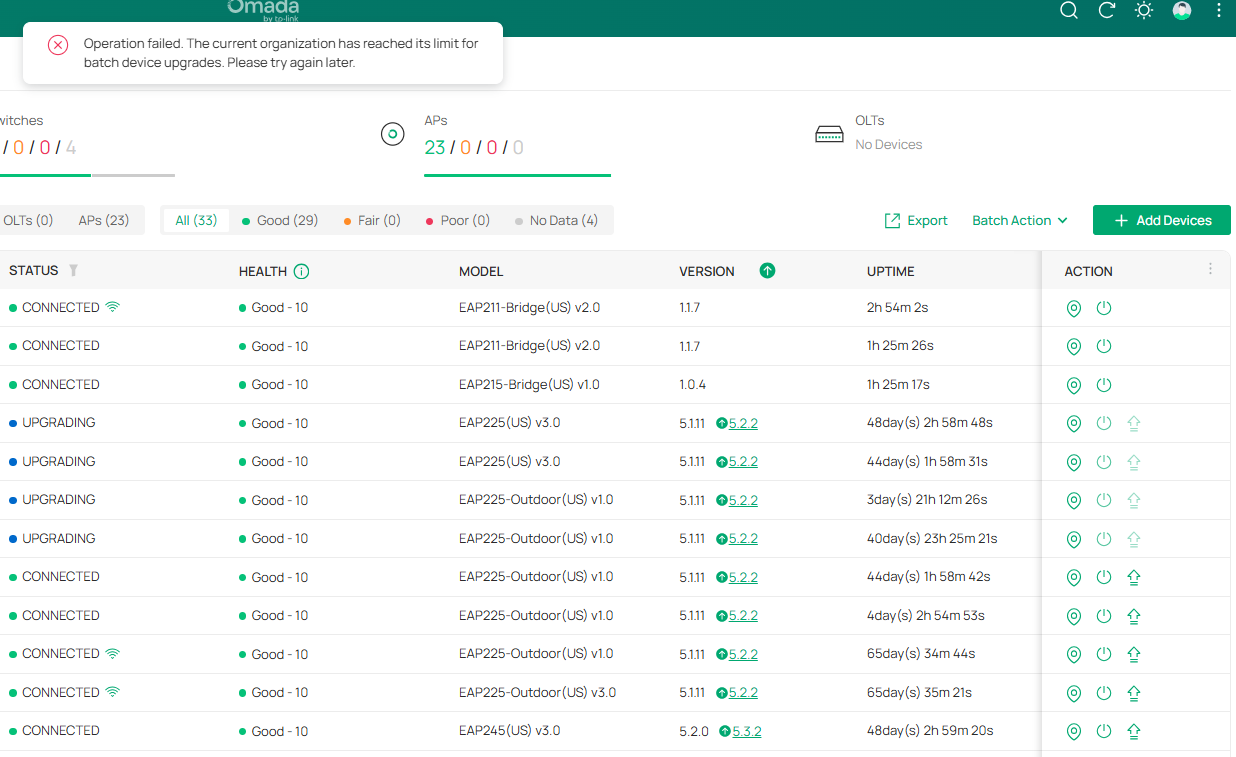
The more devices on a controller, the worse the FW upgrade gets. I have two OC300, one OC200 and one ER7212PC. I had no trouble with OC200 and ER7212PC as they have only a handfull of devices, but both OC300 have been a nightmare to keep up to date. In fact untill today where I notices one of the maybe 30+ upgrade pending devices had a hours instead of days UPTIME, I hadn't been able to keep these 2 OC300 devices upgraded.
This is worsened by the fact that it seems many devices are not straightly upgraded to the latest firmware, but to the next one if there have been more than one since its current version, which on the devices page still shows up as upgrade pending.
I've had lots of trouble with FW update on remote site before which turned out to be ISP blocking new ports, but now I can't upgrade the devices on the local site to keep up with the constant stream of new FWs. And the fact that there is no actual feedback whatsoever on the FW update process that doesn't requiere staring at the screen and manually taking notes, makes the whole thing so much worse and frustrating.
Now that I managed to upgrade just 4 devices, I can manually upgrade another 4. Ridiculous. This is after the previous 7 attempts using the Global -> Firmware -> One-Time Upgrade massively failed.
Seems like Golbal-> Firmware is still in beta despite no longer showing the beta logo/comment.